±ΨΧϊΉνΚσ”… liuxing ”Ύ 2013-4-15 22:23 ±ύΦ≠
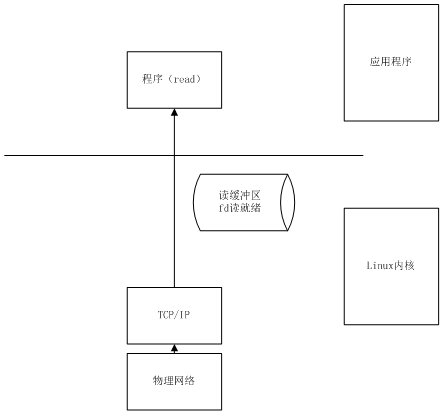
LinuxΫΪΥυ”–Άβ≤Ω…η±ΗΕΦΩ¥Ήω“ΜΗωΈΡΦΰά¥Ϋχ––≤ΌΉςΓΘ“ρ¥ΥΘ§linuxΕ‘Υυ”–Άβ≤Ω…η±ΗΒΡ≤ΌΉςΕΦΩ…“‘Ω¥Ήω «ΈΡΦΰΒΡ≤ΌΉςΓΘΈΡΦΰΒΡ≤ΌΉςΒ±»Μ–η“Σ”–Ηω±ξ ΨΟη ωΥϋΘ§’βΨΆ «ΈΡΦΰΟη ωΖϊΘ®file descriptorΘ©ΓΘ linuxΒΡIO≤ΌΉς»γΚΈ–ΈœσάμΫβΡΊΘΩΈ“Ο«ΥΒΆχ¬γsocketΒΡreadΘ®Θ© «“ΜΗωIO≤ΌΉςΟϋΝνΘ§ΨΏΧεΝς≥Χ «’β―υΒΡΘΚ ”Π”Ο≥Χ–ρΒς”ΟreadΟϋΝνΘ§Ά®÷ΣΡΎΚΥ–η“ΣΉωΕΝ»Γ ΐΨί≤ΌΉς ΡΎΚΥ¥¥Ϋ®“ΜΗωΈΡΦΰΟη ωΖϊ ΡΎΚΥ¥”Έοάμ≤ψ ’ΒΫΕΝ ΐΨίΒΡΟϋΝνΘ§¥”Άχ¬γ÷–Μώ»Γ ΐΨίΑϋ ΐΨίΑϋ¥ΪΒίΒΫTCP/IP≤ψΘ§ΫβΈω ΐΨίΑϋΒΡΆΖ ΡΎΚΥΫΪ ΐΨίΑϋΜΚ¥φ‘ΎΈΡΦΰΟη ωΖϊΒΡΕΝΜΚ¥φ«χΘ®Ϋ” ήΜΚ¥φ«χΘ©÷–Θ§ΉΔ“β’βάοΒΡΕΝΜΚ¥φ«χ «‘ΎΡΎΚΥ÷–ΒΡ Β±ΈΡΦΰΟη ωΖϊΕΝΜΚ¥φ«χ ΐΨίΉ÷ΫΎ ΐ¥σ”Ύ”Π”Ο≥Χ–ρΕ®“εΒΡΒΆΥ°ΈΜΒΡ ±ΚρΘ®readΒΡ“ΜΗω≤Έ ΐΘ©Θ§¥Υ ±ΈΡΦΰΟη ωΖϊ¥Π”ΎΕΝΨΆ–ςΒΡΉ¥Χ§ ΫΪΕΝΜΚ¥φ«χ÷–ΒΡ ΐΨίΗ¥÷ΤΒΫ”Π”Ο≥Χ–ρΘ®”ΟΜß«χΘ©ΖΒΜΊ ![]()
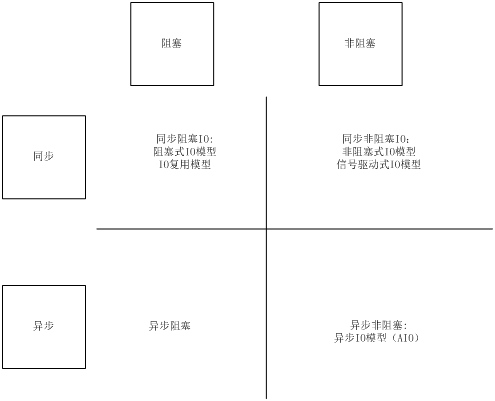
’βάο–η“ΣΥΒΟςΒΡ « 1 ΟΩΗωΈΡΦΰΟη ωΖϊΕΦ”–Ή‘ΦΚΒΡΕΝΜΚ≥ε«χΚΆ–¥ΜΚ≥ε«χΘ§ΕΝΜΚ≥ε«χΕ‘”ΠΒΡ «read≤ΌΉςΘ§–¥ΜΚ≥ε«χΕ‘”ΠΒΡΨΆ «write≤ΌΉςΝΥ 2 ΕΝΜΚ≥ε«χΚΆ–¥ΜΚ≥ε«χΕΦ «‘ΎΡΎΚΥ«χ÷– IOΡΘ–Άœ÷”–ΒΡlinux IOΡΘ–Ά”–5÷÷ΘΚ Ήη»ϊ ΫIOΡΘ–ΆΘ§Ζ«Ήη»ϊ ΫIOΡΘ–ΆΘ§IOΗ¥”ΟΡΘ–ΆΘ§–≈Κ≈«ΐΕ· ΫIOΡΘ–ΆΘ§“λ≤ΫIOΡΘ–Ά Ψ≠≥Θ≈Σ≤Μ«ε≥ΰΒΡΨΆ «Ήη»ϊΘ§Ζ«Ήη»ϊΘ§“λ≤ΫΘ§Ά§≤Ϋ …œΆΦΗχ≥ωΒΡΆ§≤Ϋ“λ≤Ϋ±ξΉΦ «ΘΚ ΐΨίΟη ωΖϊΜΚ¥φ «”…Υ≠ά¥Ϋχ––ΕΝ»ΓΒΡΘΩ”…”ΟΜß≥Χ–ρΕΝ»ΓΘ§‘ρ≈–ΕœΈΣΆ§≤ΫΘΜ”…ΡΎΚΥΆΤΥΆΘ§≈–ΕœΈΣ“λ≤ΫΓΘ …œΆΦΗχ≥ωΒΡΉη»ϊΖ«Ήη»ϊ±ξΉΦ «ΘΚΒς”ΟΒΡ”ΟΜßΫχ≥Χ «Ζώ «Ήη»ϊΒΡΉ¥Χ§ΓΘ ΧβΆβΜΑΘΚΙΊ”Ύ“λ≤ΫIOΡΘ–Ά- Βœ÷”–”ΟΜß≤ψ Βœ÷ΩβglibcΚΆΡΎΚΥlibaioΘ®kernel 2.6Θ©-Υ≥±ψΥΒ“ΜΨδlibaioΙΛ“ΒΦΕ±π Ι”ΟΒΡΖΕάΐ”–OceanBase «Χ‘±Π―–ΖΔΒΡ“ΜΧΉΖ÷≤Φ Ϋ NoSQL ΐΨίΩβœΒΆ≥Θ§‘¥¥ζ¬κ‘Ύ’βάοhttps://github.com/alibaba/oceanbase |